1. with_items:
Sometimes
we want to do many things with single tasks like installing many
packages with the same tasks just by changing the arguments. This can be
achieved using the
with_items clause.
By using the
with_items, ansible creates a temporary variable called {{item}}
which consist the value for the current iteration. Let’s have some
example to understand this. We will install few packages with below
playbook.# Installing packages individually ( Slower Process )- name: Installing Git apt: name: git update_cache: yes- name: Installing nginx apt: name: nginx update_cache: yes- name: Installing memcached apt: name: memcached update_cache: yes
The
above playbook will run 3 tasks each for installing individual package.
Rather than specifying three different tasks, we can use
with_items and specify the list of packages that we need to install.# Installing Packages with one Task ( Faster Process )- name: Installing Packages apt: name: "{{ item }}" update_cache: yes with_items: - git - nginx - memcached
Here, while executing the task “Installing packages” Ansible will read the list from
with_items and install packages one by one. You can also use with_items
with roles as well. So if you have any custom role defined and you want
to execute that role multiple times, rather than defining it multiple
times you can use with_items and just pass your elements.2. Facts Gathering
In
Ansible, Facts are nothing but information that we derive from speaking
with the remote system. Ansible uses setup module to discover this
information automatically. Sometime this information is required in
playbook as this is dynamic information fetched from remote systems.
192.168.56.7 | SUCCESS => {
"ansible_facts": {
"ansible_all_ipv4_addresses": [
"172.17.0.1",
"10.0.2.15",
"192.168.56.7"
],
( many more facts)...
It
becomes a time consuming process in Ansible as it has to gather
information from all the hosts listed in your inventory file. We can
avoid this situation and speed up our play execution by specifying
gathering_facts to false in playbook.---- hosts: web gather_facts: False
We
can also filter the facts gathering to save some time.This case is
mainly useful when you want only hardware or network information that
you want to use in your playbook. So rather than asking for all facts,
we can minimize this by only asking network or hardware facts to save
some time. To do this, you have to keep
gather_facts to True and also pass one more attribute named gather_subset to fetch specific remote information. Ansible supports network, hardware, virtual, facter, ohai as subset. To specify subset in your playbook you have to follow the below example.- hosts: web
gather_facts: True
gather_subset: network
To specify multiple subsets , you can combine then using comma (ex. network, virtual)
- hosts: web
gather_facts: True
gather_subset: network,virtual
Sometimes there might be requirement for creating local custom facts on remote machines. This can be achieved by creating
.fact file under /etc/ansible/facts.d/ location on remote machine. The .fact
file can have JSON, INI or executable file returning JSON. For example,
I have created a file called local.fact under
/etc/ansible/facts.d/local.fact and defined with following value.[general]
sample_value=1
sample_fact=normal
By
default, you will get these facts whenever you gather fact on the
remote server you defined this. If you want to filter the facts, you can
use the below command.
ansible all -i local -m setup -a "filter=ansible_local" 192.168.56.7 | SUCCESS => { "ansible_facts": { "ansible_local": { "prefrences": { "general": { "sample_fact": "normal", "sample_value": "1" } } } }, "changed": false, "failed": false }
3. any_errors_fatal
Sometime
it is desired to abort the entire play on failure of any task on any
host. This can be helpful in a scenario where you are deploying any
service on group of hosts and if any failure occurred on any server
should fail the entire play because we don’t want the deployments to be
partial on any server.
---
- hosts: web
any_errors_fatal: true
The
any_error_fatal option will mark all the hosts as failed if fails and immediately abort the playbook execution.4. max_fail_percentage
Ansible
is designed in such a way that it will continue to execute the playbook
until and unless there are any hosts in the group that are not yet
failed. Sometimes it becomes issue while doing deployments because its
not maintaining consistency. Consider scenario’s where you have 100+
servers attached to load balancer and you are targeting for zero
downtime with rolling updates. As Ansible supports rolling updates and
you can define the batch size( Batch size is nothing but the number of
servers you want to target for deployment in rolling updates, you can
also provide %), you have to monitor these deployments for failure and
take decision when to call it off.
max_fail_percentage allows you to abort the play if certain threshold of failures have been reached.---
- hosts: web
max_fail_percentage: 30
serial: 30
If 30 of the servers to fail out of 100. Ansible will abort the rest of the play.
5. run_once
There
are condition where we have to write our playbook in such a way that
will run some tasks or perform some action only on single host from
group. If you are thinking of Handlers do the same thing. Think twice
because even though multiple tasks notify to perform some action,
handlers will only gets executed after all tasks completed in play but
on all hosts and not on single.
--- - hosts: webtasks: - name: Initiating Database script: initalize_wp_database.sh run_once: true
To achieve this, Ansible provided
run_once
module, which will run only on single host from group of hosts. By
default, Ansible will select the first host from the group to execute.
This can also be used with delegate_to to run the task on specific server. When executed with serial, task marked as run_once gets executed on one host from each batch.6. Ansible Vault
There
are scenarios where we have to keep sensitives information in playbook,
like database username and password. Keeping such sensitive information
open is not a good idea as we are going to keep our playbook in version
control system. To Keep such information, Ansible provided Vault to
store such information in encrypted format.
Ansible
Vault can be used to encrypt binary files, group_vars, host_vars,
include_vars and var_files. Ansible vault can be used with command line
tool named
ansible-vault.You can create encrypted file using following command.ansible-vault create encryptme.yml
If
you are running this command for first time, it will ask you for
setting vault password. Later you have to provide the same while running
ansible-playbook command using
--ask-vault-pass.
To encrypt any file, you can use the following command
ansible-vault encrypt filename.yml
This will encrypt all your content and can only be decrypted using vault password.
Since
Ansible 2.4
you can have multiple vault passwords. The reason for allowing multiple
passwords is because you cannot encrypt dev and prod passwords using
single vault password. The passwords for environments dev will be
different, than prod environment. Now, if anyone who has dev vault
password would not be able to decrypt prod password which makes it more
secure. The Vault credentials are encrypted through vault-id. Please follow below examples for creating multiple vault passwords.ansible-vault --new-vault-id dev --new-vault-password-file=development encrypt dev_config.ymlansible-vault --new-vault-id prod --new-vault-password-file=production encrypt prod_config.yml
The
vault-id is used for decrypting the passwords. The vault-id dev is used to encrypt dev_config.yml whereas vault-id prod is used to encrypt prod_config.yml. To decrypt, we use the following command.ansible-vault --vault-id prod@prompt decrypt prod_config.yml
This command will ask vault password for vault-id prod.
7. No_logs
In
previous section, we covered how we can encrypt the data using Ansible
Vault and share it publicly. But this encrypted data is exposed when we
run the playbook in -v(verbose) mode. Anyone who has access to
controller machine or Ansible Tower jobs, they can easily identify the
encrypted data by running the playbook in verbose mode.

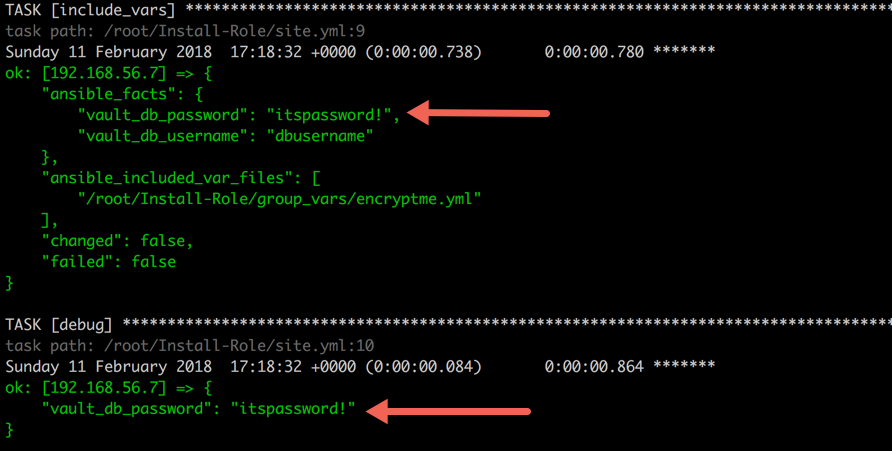
In
above screenshot, you can see that the encrypted data is exposed in
ansible_facts. To secure or censor such information, Ansible has provide
a keyword named
no_log which you can set to true to keep any task’s information censored.--- - hosts: web tasks: - include_vars: group_vars/encrypted_data.yml no_log: true - name: Printing encrypted variable debug: var: vault_db_password no_log: true


This
way you can keep verbose output but hide sensitive information from
others. This can also be applied to play but it becomes difficult for
debug and not recommended.
Note that when debugging Ansible withANSIBLE_DEBUG, theno_logscannot stop ansible from showing the information.
8. tags
Sometimes
while writing the playbook we never think about dividing the playbook
logically and we end up with a long playbook. But what if we can divide
the long playbook into logical units. We can achieve this with
tags, which divides the playbook into logical sections.
Ansible Tags are supported by tasks and play. You can use
tags
keyword and provide any tag to task or play. Tags are inherited down to
the dependency chain which means that if you applied the tags to a role
or play, all tasks associated under that will also get the same tag.--- - hosts: web tasks: - name: Installing git package apt: package: git tags: - package - name: Running db setup command command: setupdb.sh tags: - dbsetup
To run your playbook with specific tag, you have to provide command line attribute
--tags and name of your tag.ansible-playbook -i local site.yml --tags package
Above
command will run tasks which are tagged as package and skip all other
tasks. Sometimes you have to play complete playbook and skip some part.
This can be achieved with
--skip-tag attribute.ansible-playbook -i local site.yml --skip-tags package
The above command will run all tasks and skip tasks tagged with package.If you want to list all tags, that can be done with
--list-tag attribute.
Ansible also provided some special tags as
always, tagged, untagged and all.ansible-playbook -i local site.yml --skip-tags always
By default , ansible runs with--tags allwhich will execute all tasks.
9. command module idempotent (optional)
As
we know that all modules are idempotent, which means if we are running a
module multiple times should have the same affect as running it just
once. To implement idempotency, you have to check module whether its
desired state has been achieved or not. If its already achieved then
just exit or else perform the action specified. Mostly all Ansible
modules are idempotent but there are few modules which are not. Command
and Shell modules of Ansible are not idempotent. But there are ways to
make them idempotent. Let’s see how we can make them idempotent.
Command module runs same command again and again. To make it idempotent we can use the attribute
create or remove. When used with create
attribute, Ansible will only run the command task if the file specified
by the pattern does not exists. Alternatively you could use remove, which will only execute the task if the file specified exists.tasks:- name: Running command if file not present command: setup_db.sh args: creates: /opt/database
As
Ansible supports idempotent, make sure you use all such modules in your
playbook to make your play idempotent so that re-running should be
safe.
10. Debugging Playbook on Run
Debugging
an ansible playbook is one of the coolest feature that ansible has
introduced(in 2.1 version). While we develop any playbook sometimes we
see failures and to debug we usually run the playbook again, identify
the error that Ansible throws and modify the playbook and then rerun the
playbook. What if your playbook takes 30 minutes to run and your play
is failing for last few tasks and after debugging you will again run
your playbook for almost 30 minutes. I guess that’s ideal way to debug,
You can used the ansible debug strategy.
Ansible
provides a debug strategy which will help to enable the debugger when a
task fails. It will provide access to all features of the debugger in
the context of failed task. This way if you encounter a failed task, you
can set the values of the variables, update the module arguments and
re-run the failed task with new arguments and variables.
To use the debug strategy in your playbook, you have to define the strategy as debug.
--- - hosts: web strategy: debug tasks: ...
With Debugger, it provides multiple commands to debug your failed tasks.
P task/host/result/vars ->Prints the value to executed a module
task.args[key] = value — upgrade the module arguments
vars[args]=value — set argument value
r(edo) — run the task again
c(continue) — Just continue
q(uit) — quit from debugger
Let’s run the following playbook to demonstrate this feature.
--- - hosts: web strategy: debugvars: package: "nginx" tasks: - name: Install Git Package apt: name: "{{ new_package }}"
Note: the debugger doesn’t work with debug module, so if you have any undefined variables it will not work.