
What is Sqoop in Hadoop?
Apache Sqoop is an effective hadoop tool used for importing/Exporting data from RDBMS’s like MySQL, Oracle, etc. into
HBase, Hive or HDFS.How Apache Sqoop works?
Once the input is recognized by Sqoop hadoop, the metadata for the table is read and a class definition is created for the input requirements. In reality, the dataset being transferred is split into partitions and map only jobs are launched for each partition with the mappers managing transferring the dataset assigned to it.Challenges with data ingestion in Hadoop ?
- parallel processing
- data quality
- machine data on a higher scale of several gigabytes per minute
- multiple source ingestion
- real-time ingestion and scalability
- Structured and Unstructured data
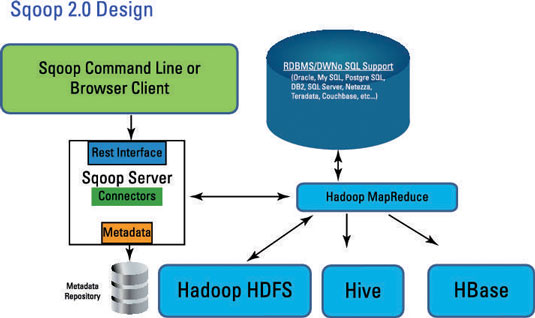
Sqoop 1.0 Design:

Sqoop provides many salient features like:
- Full/Incremental Load
- Parallel import/export
- Import results of SQL query
- Compression
- Connectors for all major RDBMS Databases
- Kerberos Security Integration
- Load data directly into Hbase/Hive/HDFS file system
- Support for Accumulo
Import process:

Export process:

Basic Commands and Syntax for Sqoop:
Note: place mysql-connector-java-5.1.18-bin in lib folder of Sqoop
List available databases/tables :
$ sqoop list-databases --connect jdbc:mysql://localhost/userdb --username root --password 123
$ sqoop list-tables --connect jdbc:mysql://localhost/userdb --username root --password 123
Import Data from MySql into HDFS :
$ sqoop import --connect jdbc:mysql://localhost/userdb --username root --password 123
--table emp --m 1 --target-dir /queryresult
Executing command using options-file :
$ sqoop list-tables --options-file SqoopImportOptions.txt
Sample options-file:
##############################
# Start of Options file for sqoop import
##############################
--connect
jdbc:mysql://localhost/userdb
--username
root
--password
123
##############################
# End of Options file for sqoop import
##############################
Check file created in HDFS :
$ hadoop fs -cat /queryresult/part*
Import all rows, but specific columns of the table :
$ sqoop import --options-file SqoopImportOptions.txt --table emp --columns "empno,ename" --as-textfile -m 1 --target-dir /queryresult
Import all columns, filter rows using where clause :
$ sqoop --options-file SqoopImportOptions.txt --table emp --where "empno > 7900" --as-textfile -m 1 --target-dir /user/sqoop-mysql/employeeGtTest
Import with a free form query with where clause :
$ sqoop --options-file SqoopImportOptions.txt --query 'select empno,ename,sal,deptno from emp where EMP_NO < 7900 AND $CONDITIONS' -m 1 --target-dir /user/sqoop-mysql/employeeFrfrmQry1
Controlling Parallelism :
Sqoop imports data in parallel from most database sources. You can specify the number of map tasks (parallel processes) to use to perform the import by using the -m or --num-mappers argument.
When performing parallel imports, Sqoop needs a criterion by which it can split the workload. Sqoop uses a splitting column to split the workload. By default, Sqoop will identify the primary key column (if present) in a table and use it as the splitting column. The low and high values for the splitting column are retrieved from the database, and the map tasks operate on evenly-sized components of the total range.If the actual values for the primary key are not uniformly distributed across its range, then this can result in unbalanced tasks. You should explicitly choose a different column with the --split-by argument. For example, --split-by employee_id.
Note: Sqoop cannot currently split on multi-column indices. If your table has no index column, or has a multi-column key, then you must also manually choose a splitting column.
Split by refer section on controlling parallelism :
$ sqoop --options-file SqoopImportOptions.txt --query 'select EMP_NO,FIRST_NAME,LAST_NAME from employees where $CONDITIONS' --split-by EMP_NO --direct --target-dir /user/sqoop-mysql/SplitByExampleImport
Boundary query
Again related to controlling parallelism..
--boundary-query “SELECT MIN(EMP_NO), MAX(EMP_NO) from employees”
Fetch size
This argument specifies to sqoop the number of entries to read from database at once.
--fetch-size=5
Compression
Use the --compress argument to enable compression; If you dont specify a compression codec (--compression-codec), the default gzip will be used.
The command:
$ sqoop --options-file SqoopImportOptions.txt \
--query 'select EMP_NO,FIRST_NAME,LAST_NAME from employees where $CONDITIONS' \
-z \
--split-by EMP_NO \
--direct \
--target-dir /user/airawat/sqoop-mysql/CompressedSample
The output:
$ hadoop fs -ls -R sqoop-mysql/CompressedSample | grep part*
Import all tables
$ sqoop --options-file SqoopImportAllTablesOptions.txt --direct --warehouse-dir sqoop-mysql/EmployeeDatabase
Import formats
With mysql, text file is the only format supported; Avro and Sequence file formatted imports are feasible through other RDBMS
Sqoop code-gen
Generate jar and class file for employee table
$ sqoop codegen --connect jdbc:mysql://cdh-dev01/employees \
--username myUID \
--password myPWD \
--table employees \
--outdir /user/airawat/sqoop-mysql/jars
Files created:
$ ls /tmp/sqoop-airawat/compile/879394521045bc924ad9321fe46374bc/
employees.class employees.jar employees.java
Copy files to your home directory:
cp /tmp/sqoop-airawat/compile/879394521045bc924ad9321fe46374bc/* .