What is Hive ?
- Hive is SQL for Hadoop cluster.
- It is an open source data warehouse system on top of HDFS that adds structure to the data.
- It provides SQL like interface which is known as "Hive Query Language (HQL)".
- We write the query in HQL which translate into Map-Reduce code and run the same on cluster.

The main components of Hive are:
- Metastore: It stores all the metadata of Hive. It stores data of data stored in database, tables, columns, etc..
- Driver: It includes compiler, optimizer and executor used to break down the Hive query language statements.
- Query compiler: It compiles HiveQL into DAG graph of map reduce tasks.
- Execution engine: It executes the tasks produces by compiler.
- Thrift server: It provides an interface to connect to other applications like MySQL, Oracle, Excel, etc. through JDBC/ODBC drivers.
- Command line interface: It is also called Hive shell. It is used for working with data either interactively or batch data processing.
- Web Interface: It is a visual structure on Hive used for interaction with data
- SerDe : Serializer, Deserializer gives instructions to hive on how to process a record.
Data Storage in Hive:
Hive has different forms of storage options and they include:
- Metastore: Metastore keeps track of all the metadata of database, tables, columns, datatypes etc. in Hive. It also keeps track of HDFS mapping. The default Metastore is DerBy Database.
- Tables: There can be 2 types of tables in Hive.
First, normal tables (managed/internal tables) like any other table in database.
Second, external tables (un-managed tables) which are like normal tables except for the deletion part. HDFS mappings are used to create external tables which are pointers to table in HDFS.
The difference between the two types of tables is that when the external table is deleted its data is not deleted. Its data is stored in the HDFS whereas in case of normal table the data also gets deleted on deleting the table. - Partitions: Partition is slicing of tables that are stored in different subdirectory within a table’s directory. It enhances query performance especially in case of select statements with “WHERE” clause.
- Buckets: Buckets are hashed partitions and they speed up joins and sampling of data.
Hive and RDBMS are very similar but they have different applications and different schemas that they are based on.
- RDBMS are built for OLTP (Online transaction processing) that is real time reads and writes in database. They also perform little part of OLAP. (online analytical processing).
- Hive is built for OLAP that is real time reporting of data. Hive
does not support inserting into an existing table or updating table data
like RDBMS which is an important part of OLTP process.
All data is either inserted in new table or overwritten in existing table. - RDBMS is based on write schema that means when data is entered in the table it is checked against the schema of table to ensure that it meets the requirements. Thus loading data in RDBMS is slower but reading is very fast.
- Hive is based on read schema that means data is not checked when it is loaded so data loading is fast but reading is slower.
Hive Query Language (HQL)
HQL is very similar to traditional database. It stores data in tables, where each table consists of columns
- Data Definition statements (DDL) like create table, alter table, drop
table are supported.
All these DDL statements can be used on Database, tables, partitions, views, functions, Index, etc. - Data Manipulation
statements (DML) like load, insert, select and explain are supported.
Load is used for taking data from HDFS and moving it into Hive.
Insert is used for moving data from one Hive table to another.
Select is used for querying data. Explain gives insights into structure of data.
Hive Commands :
Data Definition Language (DDL) :
Example : CREATE, DROP, TRUNCATE, ALTER, SHOW, DESCRIBE Statements.
Go to Hive shell by giving the command sudo hive and
Enter the command ’create database ’ to create the new database in the Hive.
Enter the command ’create database ’ to create the new database in the Hive.

To list out the databases in Hive warehouse, enter the command ‘show databases’.

The database creates in a default location of the Hive warehouse.
In Cloudera, Hive database store in a /user/hive/warehouse.
The command to use the database is USE

Copy the input data to HDFS from local by using the copy From Local command.
Copy the input data to HDFS from local by using the copy From Local command.
{kind=link}
Data Manipulation Language (DML) : Retrieving Information
| Function | MySQL | Hive |
| Retrieving Information (General) | SELECT from_columns FROM table WHERE conditions; |
SELECT from_columns FROM table WHERE conditions; |
| Retrieving All Values | SELECT * FROM table; |
SELECT * FROM table; |
| Retrieving Some Values | SELECT * FROM table WHERE rec_name = "value"; |
SELECT * FROM table WHERE rec_name = "value"; |
| Retrieving With Multiple Criteria | SELECT * FROM TABLE WHERE rec1 = "value1" AND rec2 = "value2"; |
SELECT * FROM TABLE WHERE rec1 = "value1" AND rec2 = "value2"; |
| Retrieving Specific Columns | SELECT column_name FROM table; |
SELECT column_name FROM table; |
| Retrieving Unique Output | SELECT DISTINCT column_name FROM table; |
SELECT DISTINCT column_name FROM table; |
| Sorting | SELECT col1, col2 FROM table ORDER BY col2; |
SELECT col1, col2 FROM table ORDER BY col2; |
| Sorting Reverse | SELECT col1, col2 FROM table ORDER BY col2 DESC; |
SELECT col1, col2 FROM table ORDER BY col2 DESC; |
| Counting Rows | SELECT COUNT(*) FROM table; |
SELECT COUNT(*) FROM table; |
| Grouping With Counting | SELECT owner, COUNT(*) FROM table GROUP BY owner; |
SELECT owner, COUNT(*) FROM table GROUP BY owner; |
| Maximum Value | SELECT MAX(col_name) AS label FROM table; |
SELECT MAX(col_name) AS label FROM table; |
| Selecting from multiple tables (Join same table using alias w/”AS”) | SELECT pet.name, comment FROM pet, event WHERE pet.name = event.name; |
SELECT pet.name, comment FROM pet JOIN event ON (pet.name = event.name) |
Using Metadata :
| Function | MySQL | Hive |
| Selecting a database | USE database; |
USE database; |
| Listing databases | SHOW DATABASES; |
SHOW DATABASES; |
| Listing tables in a database | SHOW TABLES; |
SHOW TABLES; |
| Describing the format of a table | DESCRIBE table; |
DESCRIBE (FORMATTED|EXTENDED) table; |
| Creating a database | CREATE DATABASE db_name; |
CREATE DATABASE db_name; |
| Dropping a database | DROP DATABASE db_name; |
DROP DATABASE db_name (CASCADE); |
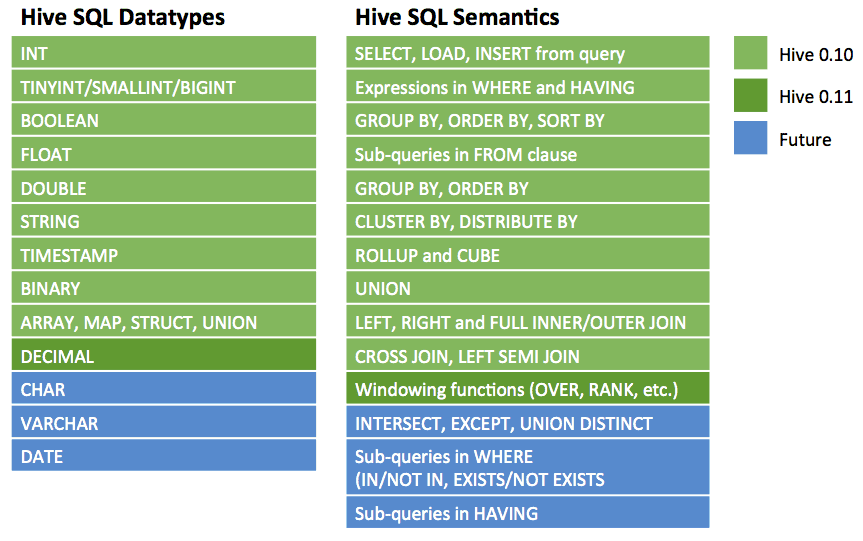
Current SQL Compatibility
Hive Command Line :
| Function | Hive |
| Run Query | hive -e 'select a.col from tab1 a' |
| Run Query Silent Mode | hive -S -e 'select a.col from tab1 a' |
| Set Hive Config Variables | hive -e 'select a.col from tab1 a' -hiveconf hive.root.logger=DEBUG,console |
| Use Initialization Script | hive -i initialize.sql |
| Run Non-Interactive Script | hive -f script.sql |
The .hiverc file :
What is .hiverc file?
It is a file that is executed when you launch the hive shell - making it an ideal place for adding any hive configuration/customization you want set, on start of the hive shell. This could be:
- Setting column headers to be visible in query results
- Making the current database name part of the hive prompt
- Adding any jars or files
- Registering UDFs
.hiverc file location
The file is loaded from the hive conf directory.
If the file does not exist, you can create it.
It needs to be deployed to every node from where you might launch the Hive shell.
Sample .hiverc
add jar /home/airawat/hadoop-lib/hive-contrib-0.10.0-cdh4.2.0.jar;
set hive.exec.mode.local.auto=true;
set hive.cli.print.header=true;
set hive.cli.print.current.db=true;
set hive.auto.convert.join=true;
set hive.mapjoin.smalltable.filesize=30000000;